IFC is technically serialisation agnostic, which means that the .ifc file (called IFC-SPF) is only one of a few ways you can store IFC data. In theory, you could equally store IFC as XML, JSON, TTL, ZIP, MSSQL, or HDF5. In practice, only IFC-SPF is battle tested and commonly used.
This is not good. Using multiple serialisations in different scenarios would be better such as JSON for online REST API partial IFC data exchange, TTL for integration with other linked data, or HDF5 for model archival with large geometry.
IFC-SPF has downsides:
-
Unordered IDs mean that you have to parse the entire text file into memory. You use a lot of memory! No lazy loading.
-
SPF is not a common serialisation so it is difficult for others to access the data without a dedicated IFC library. This limits the tools you can integrate with.
-
Geometry is not stored explicitly - it is only stored implicitly and thus needs to be converted into explicit geometry for visualisation. This sucks because visualising the model is often one of the first things someone wants to do.
-
It is stored on-disk, not via a connection. This means it's difficult to have simultaneous access or access across a network.
I've been investigating SQLite and MySQL as a possible alternative to IFC-SPF for certain usecases.
I'm not the first to do so, for example there is IfcSQL for Microsoft SQL (proprietary), supposedly an experimental SQLite variant, PG's SQLite approach, and other research, and perhaps unpublished attempts by @aothms and others but all in all there isn't much literature on the topic so here goes.
Note that some prior attempts who talk about IFC & SQL only store some IFC data, not everything (i.e. it's not really serialisation, it's more of a lossy export / translation). I want to store all data.
Some goals:
-
Fully represent all IFC data.
-
Less memory usage than SPF.
-
Provide a free software option and support free software SQL dialects. Anybody who can write an SQL query should be able to get out data (easily, we'd hope). This means DBAs, web developers, random IT folks, and Bob playing with Microsoft PowerBI.
-
Store explicit geometry alongside implicit geometry as blobs.
-
Access via a network connection or simultaneous access.
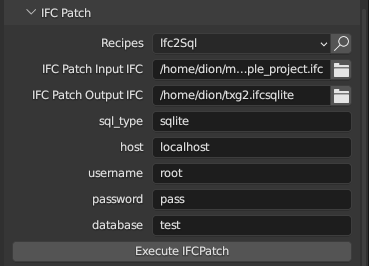
There is now an IFC2SQL IfcPatch recipe. It reads IFC-SPF into memory and then can create either IfcSQL or MySQL. In theory a pure text parser version can be written that would allow it to parse huge (many GB) of IFC-SPF but that doesn't exist yet. Update: There is now a streaming option for IFC-SPF which means you can convert almost arbitrarily large IFC-SPF into SQL. Hooray!
I see three main approaches to storing data in SQL:
-
One table per non-abstract IFC class. The schema is therefore different for each IFC version. E.g a table for IfcWall, a table for IfcDirection, a table for IfcProfileDef, etc.
-
One table per EXPRESS type. E.g. a table for entities, a table for attributes, a table for data types or similar.
-
Totally bespoke and redesigned specifically for how a user might write an SQL query in real life as opposed to academia.
The IFC2SQL recipe currently only does the first approach (one table per class) as well as adds in a few auxiliary bespoke tables (approach 3) for things like classes, geometry and psets. Approach 2 has not yet been fully investigated.
I'd like to emphasize the need for option 3. I think that IDS has done a great job at identifying which parts of a model are most commonly questioned (classes, attributes, psets, classifications, materials, and decomposition) and I believe that these are suitable candidates for bespoke tables. IFC objects have a lot of implicit relationships and information, and especially when SQL queries are expensive, it's better to have explicit information also available. In my prototype I've only included bespoke tables for classes, psets, and geometry so far.
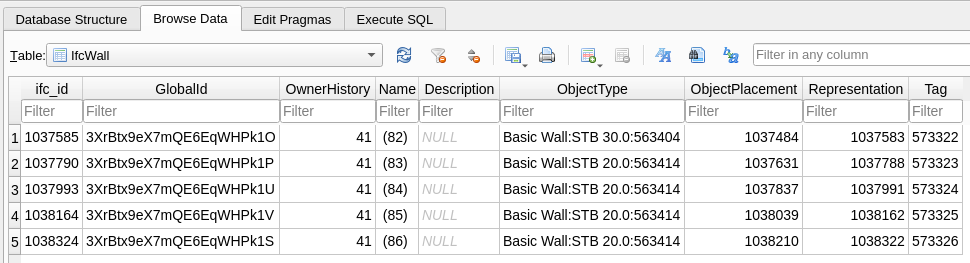
Here's what the schema looks like after converting to SQLite:

... and an individual table ...
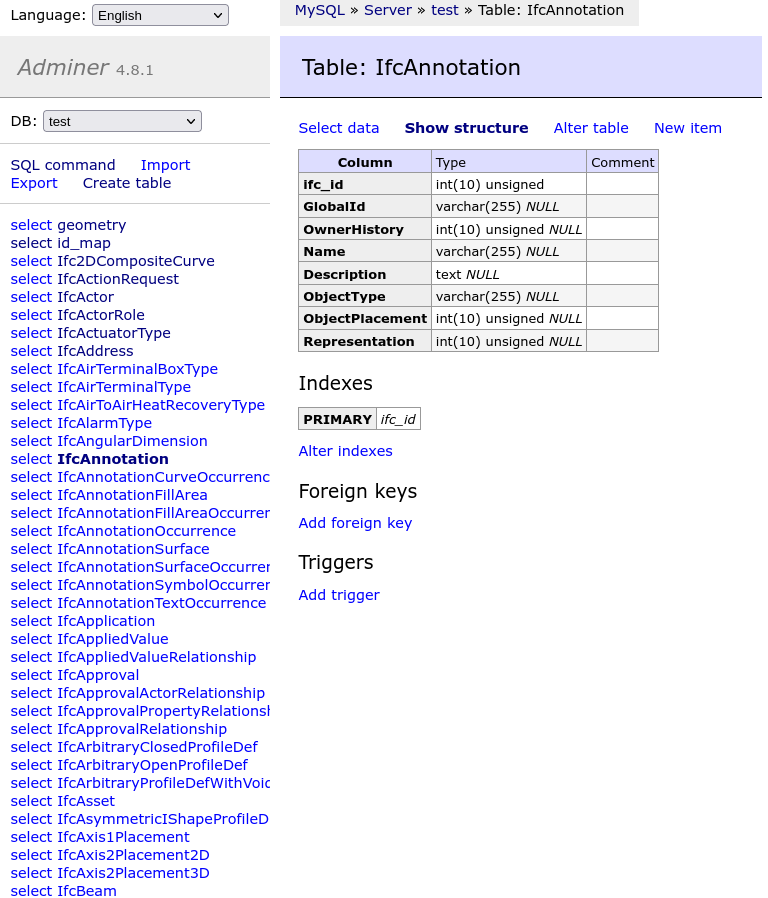
The schema is similar in MySQL but uses more nuanced data types that MySQL offers:
The IFC schema defines even more nuance like sets vs lists, selects, and logicals. The inverse relationships are not necessarily symmetric, and where are also where rules which give specific data constraints. What this means is that no serialisation can fully capture the EXPRESS definition of IFC. For example, in IFC-SPF, lists and sets are both (), inverse attributes don't exist, and attribute names themselves don't exist.
It's no different in SQL. This means that SQL will store the data, but cannot guarantee valid IFC. Foreign key triggers on update / on delete won't work as a blanket statement. The solution so far is that in any tricky situation (list, set, select) we will store data as JSON (both MySQL and SQLite support a JSON data type which is basically text with a JSON validation hook).
When you run a query against a field with JSON you can use SQL functions to expand JSON lists into individual rows. Here's what an SQLite query might look like to get all the psets and simple properties of all actuators in a model. Notice the use of json_each and json_extract:
SELECT
IfcActuator.ifc_id, IfcActuator.GlobalId, IfcActuator.Name,
IfcPropertySet.Name AS pset_name, IfcPropertySingleValue.Name AS prop_name,
json_extract(IfcPropertySingleValue.NominalValue, "$.value") as nominal_value
FROM IfcActuator
JOIN (
SELECT json_each.value AS RelatedObject, RelatingPropertyDefinition
FROM IfcRelDefinesByProperties, json_each(IfcRelDefinesByProperties.RelatedObjects)
) AS IfcRelDefinesByProperties ON IfcActuator.ifc_id = IfcRelDefinesByProperties.RelatedObject
JOIN (
SELECT ifc_id, Name, json_each.value AS HasProperties FROM IfcPropertySet, json_each(HasProperties)
) AS IfcPropertySet ON IfcPropertySet.ifc_id = IfcRelDefinesByProperties.RelatingPropertyDefinition
JOIN IfcPropertySingleValue ON IfcPropertySet.HasProperties = IfcPropertySingleValue.ifc_id
Here's the equivalent in MySQL:
SELECT
IfcActuator.ifc_id, IfcActuator.GlobalId, IfcActuator.Name,
IfcPropertySet.Name AS pset_name, IfcPropertySingleValue.Name AS prop_name,
JSON_EXTRACT(IfcPropertySingleValue.NominalValue, '$.value') as nominal_value
FROM IfcActuator
JOIN (
SELECT RelatedObject.value AS RelatedObject, RelatingPropertyDefinition
FROM IfcRelDefinesByProperties
JOIN JSON_TABLE(IfcRelDefinesByProperties.RelatedObjects, '$[*]' COLUMNS (value INT PATH '$')) AS RelatedObject
) AS IfcRelDefinesByProperties
ON IfcActuator.ifc_id = IfcRelDefinesByProperties.RelatedObject
JOIN (
SELECT ifc_id, Name, HasProperties.value AS HasProperties
FROM IfcPropertySet
JOIN JSON_TABLE(HasProperties, '$[*]' COLUMNS (value INT PATH '$')) AS HasProperties
) AS IfcPropertySet
ON IfcPropertySet.ifc_id = IfcRelDefinesByProperties.RelatingPropertyDefinition
JOIN IfcPropertySingleValue
ON IfcPropertySet.HasProperties = IfcPropertySingleValue.ifc_id
Yikes. If instead of JSON the lists were expanded and stored as individual rows a query would be simpler. The IFC2SQL script has a toggle to expand any pure entity lists / sets (i.e. so long as the list and set only stores entities, and not types):
SELECT IfcActuator.ifc_id, IfcActuator.GlobalId, IfcActuator.Name, IfcPropertySet.Name AS pset_name, IfcPropertySingleValue.Name AS prop_name, json_extract(IfcPropertySingleValue.NominalValue, "$.value") as nominal_value FROM IfcActuator
JOIN IfcRelDefinesByProperties ON IfcActuator.ifc_id = IfcRelDefinesByProperties.RelatedObjects
JOIN IfcPropertySet ON IfcPropertySet.ifc_id = IfcRelDefinesByProperties.RelatingPropertyDefinition
JOIN IfcPropertySingleValue ON IfcPropertySet.HasProperties = IfcPropertySingleValue.ifc_id
With a bespoke psets table, the SQL will look significantly simpler:
SELECT IfcActuator.ifc_id, IfcActuator.GlobalId, IfcActuator.Name, psets.pset_name, psets.prop_name, psets.nominal_value FROM IfcActuator
JOIN psets ON IfcActuator.ifc_id = psets.ifc_id
In reality though you probably wouldn't write these queries except for the 5 usecases IDS has identified, and instead rely on an ORM which is aware of the IFC schema. Aha! That's IfcOpenShell!
psets = ifcopenshell.util.element.get_psets(actuator)
I've half smashed together a bare bones IfcOpenShell file / entity_instance wrapper (i.e. basically an ORM) around SQLite. Let's see how it performs when opening a 62MB .ifc file 10 times.
import time
import psutil
import ifcopenshell
start = time.time()
files = []
for i in range(0, 10):
f = ifcopenshell.open("/home/dion/txg.ifcsqlite", format=".iosSQLite")
#f = ifcopenshell.open("/home/dion/migrate2022/dion/drive/bim/ifcs/TXG_sample_project.ifc")
files.append(f)
e = f.by_type("IfcProject")[0]
e = f.by_id(e.id())
x = e.id()
x = e.is_a()
x = e.is_a("IfcProject")
x = e.GlobalId
x = e.get_info()
print(i, time.time() - start, psutil.Process().memory_info().rss / (1024 * 1024))
Type | Time | Memory | Filesize
--- | --- | --- | ---
File | 24.5s | 7995M | 62M
SQLite | 12s | 1775M | 141M
Local MySQL | 35s | 1899M | 186M
Note that though Time and Memory refers to the script with the range(0, 10) loop (i.e. opening 10 times), Filesize refers to the single file / database. This includes all bespoke tables and geometry blobs for SQL. For MySQL (MariaDB) Filesize was reported from the Adminer UI.
Notice the significant (2-3X) filesize penalty of SQL. Note that geometry blobs is about 30% of the filesize.
I've implemented just though to means that it's a drop-in replacement to open an IfcSQLite model in the BlenderBIM Add-on. See this demonstration which shows two Blender instances opening the same model simultaneously and editing a single attribute and having it update live in the database.
Loading a model uses the geometry iterator. With explicit geometry blobs, the iterator is instead replaced with a single query to a shapes and geometry table which holds blobs:
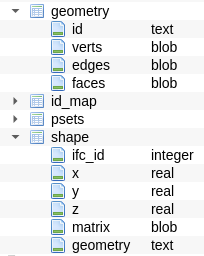
So the TXG sample model (62MB) is now loaded with these times:
Type | Time (without geometry) | Time (with geometry)
--- | --- | ---
File | 2.6s | 3.8s
SQLite | 12s | 28s Update: 4.6s
Note that the reason the time with geometry is much higher is not because of the query to the blob tables, but instead because currently the BlenderBIM Add-on runs a bunch more code that does some traversal and inverses for materials. This can potentially be cleaned up significantly, perhaps bringing the time down to about 10 seconds with geometry. Still slower, mind.
Update: if SQL stores inverses explicitly (at the expense of having to update inverse when you run an UPDATE query) the time drops dramatically down to 4.9s, getting very similar to IFC-SPF.
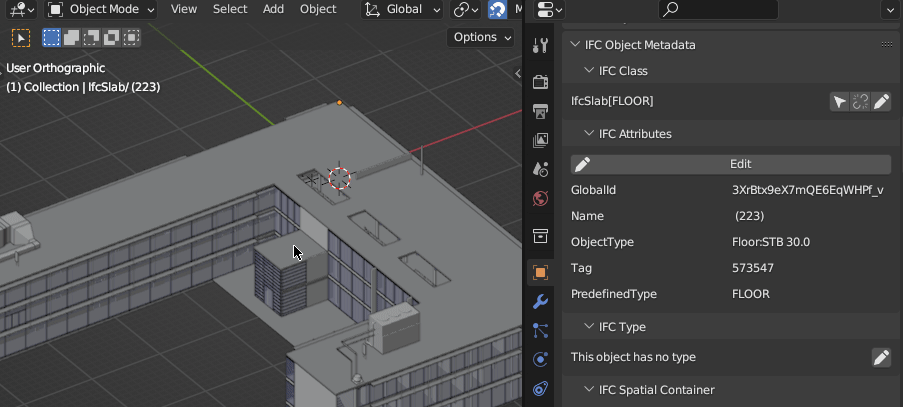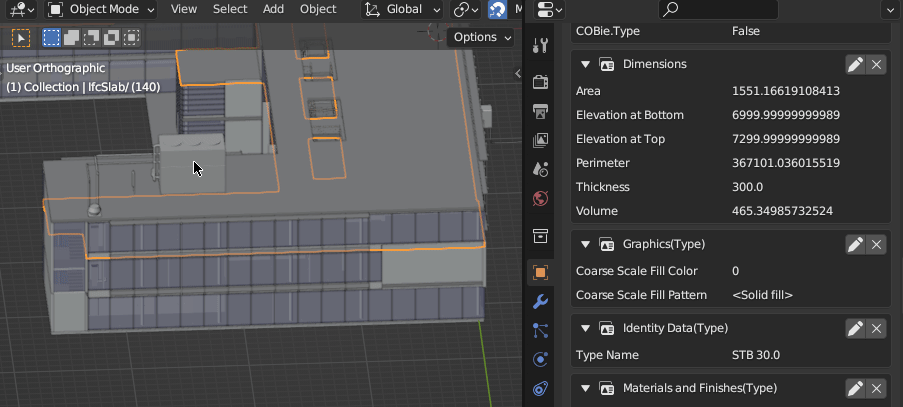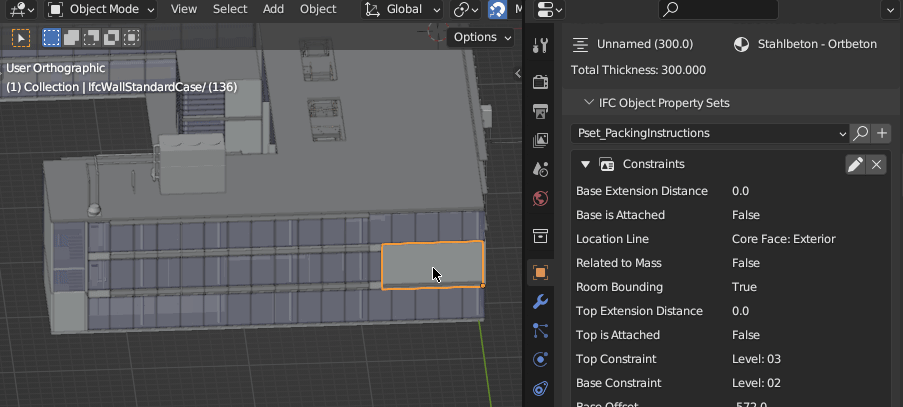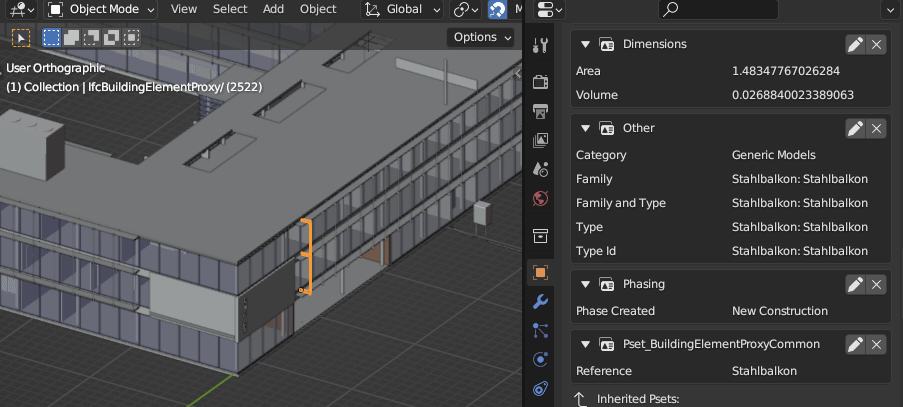
(Yes, all the data in the object properties panel are fetched on the fly from SQLite)
The wrapper implements really low-level calls like by_id, by_type, getattr, getitem, traverse, get_inverse, etc. In theory, a naive implementation will mean that for every getattr this means another SQL query is executed. This is of course absurd. This would lead to hundreds of queries for simple operations.
The solution I've used is to have a local in-memory cache of entities and attributes. This way, we can control "X" number of entities held in memory. If we want to retrieve something that isn't in memory, only then in a query run.
The current setup is that once you connect to an SQL database, it queries an id_map table and stores an in-memory dictionary of IDs (STEP IDs) and classes. This makes checking for class / ID existence very quick and can save a lot of common queries like by_id or by_type, or even when you're doing traversal or inverses it doesn't need to query class tables that we know we don't have any instances of. It also runs through all declarations in the nominated IFC version and creates some convenience lookup tables to know what possible inverses, subtypes, etc.
Once you call getattr on any forward or inverse attribute, it selects all attributes in a single query, not just the one you've selected, and caches it. Subsequent getattrs fetch from the cache instead of creating new queries. Imagine this code:
if hasattr(element, "Decomposes") and element.Decomposes:
return element.Decomposes[0].RelatingObject
This will be 2 queries instead of 4: one for Decomposes and one for RelatingObject, even though Decomposes is checked three times.
Conclusions so far:
-
You can now convert IFC to SQLite or MySQL in one click. Yay!
-
Schema aware ORMs are critical for practical purposes.
-
The IfcOpenShell "ORM" to SQL DB is semi-functional and performance isn't shockingly terrible.
-
Significantly less memory is used, and IFC entities can be lazy loaded combined with a small in-memory cache.
-
IFC-SPF in memory is always faster than running SQL queries. But the trade off is in memory usage, lazy loading, and shared access.
-
JSON data types are a quick fix to the nuances of IFC data types.
-
Writing SQL queries aren't too crazy especially if you have some bespoke tables.
-
More experimentation would be needed to see how to make inverses and traversals less expensive.
-
Some obvious things: MySQL is much heavier than SQLite, less queries are better than more queries, dealing with implicit geometry is a pain.