Does anybody maybe know how to get the filtered data from LibreOffice (.ods file) to Python. I've been reading a lot of threads on SO, but they all apply the filter in pandas.
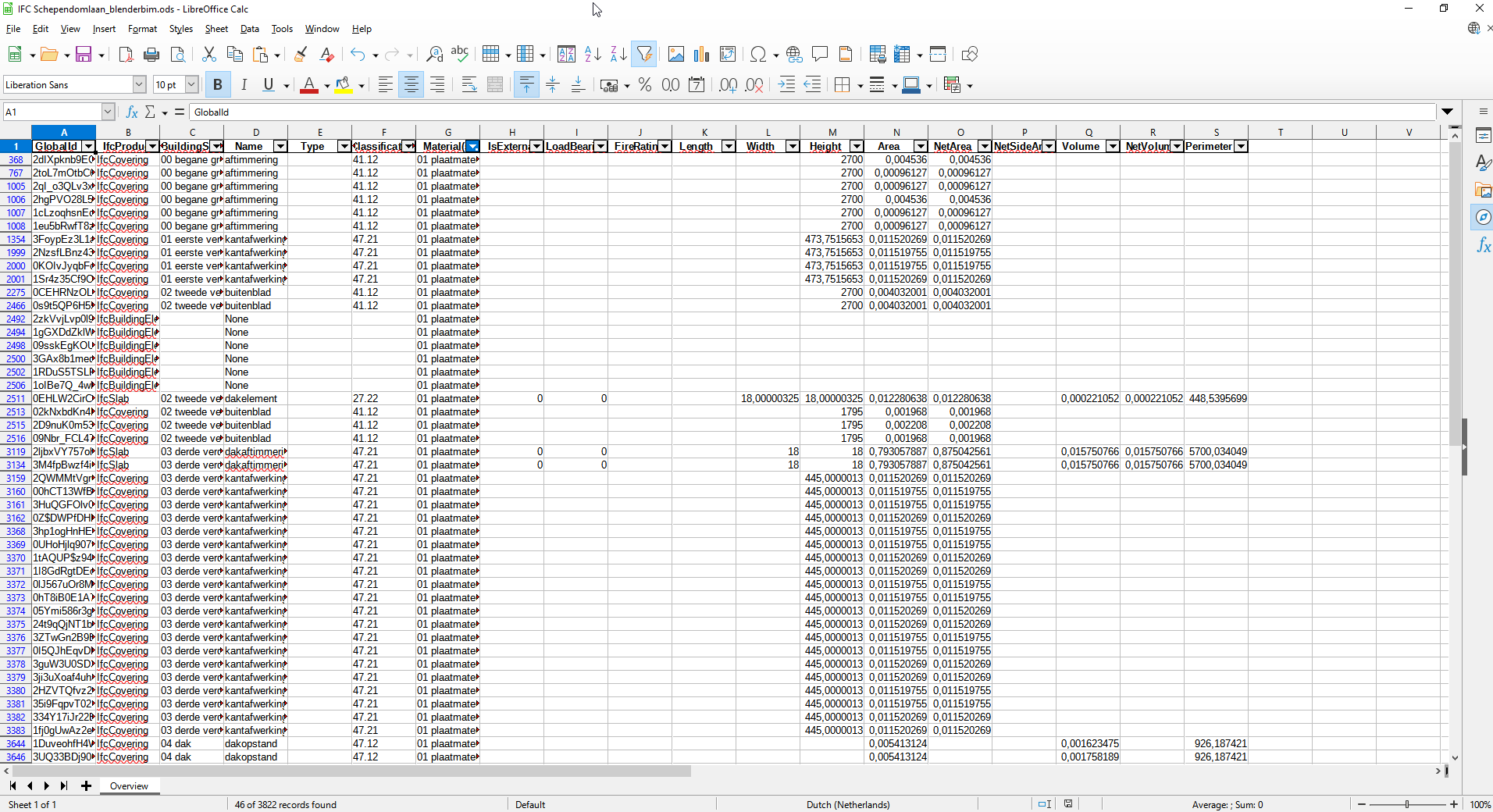
I've made this filtering in LibreOffice,
Now I want to retrieve only the GlobalId values from that filtered list
I tried:
if blenderbim_openoffice_xml_properties.my_file_path.endswith(".ods"):
###################################
### Get filtered data from .ods ###
###################################
dataframe = pd.read_excel(blenderbim_openoffice_xml_properties.my_file_path, sheet_name=blenderbim_openoffice_xml_properties.my_workbook, engine="odf")
print (dataframe['GlobalId'])
It returns each GlobalId from the .ods file. I only want the filtered items.
I can't use the openpyxl module, it's how I do it with .xlsx files like this for example:
workbook_openpyxl = load_workbook(blenderbim_openoffice_xml_properties.my_file_path)
worksheet_openpyxl = workbook_openpyxl[blenderbim_openoffice_xml_properties.my_workbook]
global_id_filtered_list = []
for row in worksheet_openpyxl:
if worksheet_openpyxl.row_dimensions[row[0].row].hidden == False:
for cell in row:
if cell in worksheet_openpyxl['A']:
global_id_filtered_list.append(cell.value)